The FTC Social Media 6b Report
My commentary on "A Look Behind the Screens: Examining the Data Practices of Social Media and Video Streaming Services - An FTC Staff Report, September 2024"

The latest FTC report offers a good baseline of what's been happening with data privacy and protections in the US. It largely mirrors my own sentiment on the matter.
Direct Link: https://www.ftc.gov/system/files/ftc_gov/pdf/Social-Media-6b-Report-9-11-2024.pdf
I've sniped more than a few references from the FTC report that I think are worth sharing - primarily so you can see the full ramifications of what has been happening and what "doing nothing" looks like. (It's not pretty.)
This is a long read, but shorter than reading the entire document yourself.
The Status Quo Is Unacceptable

First of all, what is this report and why was it created?
In December 2020, the Federal Trade Commission issued 6(b) Orders to nine of the largest social media and video streaming services—Amazon, Facebook, YouTube, Twitter, Snap, ByteDance, Discord, Reddit, and WhatsApp (“Companies”).
Some additional context on why the FTC issued the 6(b) Orders:
At the time, a bipartisan group of Commissioners issued a joint statement warning that far too much about how these platforms operate is “dangerously opaque,” with critical questions around data collection and algorithms “shrouded in secrecy.”
Unsurprisingly, they can't identify who the data has been shared with.
In fact, the Companies collected so much data that in response to the Commission’s questions, they often could not even identify all the data points they collected or all of the third parties they shared that data with.
Remember to vote...?
Despite widespread support for federal privacy standards, Congress has yet to pass comprehensive legislation on privacy, algorithmic accountability, or teen online safety. The absence of legislation has given firms nearly free rein in how much they can collect from users.
Summary of Key Findings
The term Social Media and Video Streaming Services ("SMVSS") and its acronym are utilized heavily throughout the report.
The key findings found in the report, emphasis mine:
- Many Companies collected and could indefinitely retain troves of data from and about users and non-users, and they did so in ways consumers might not expect
- Many Companies relied on selling advertising services to other businesses based largely on using the personal information of their users. The technology powering this ecosystem took place behind the scenes and out of view to consumers, posing significant privacy risks.
- There was a widespread application of Algorithms, Data Analytics, or artificial intelligence (“AI”), to users’ and non-users’ personal information. These technologies powered the SMVSSs—everything from content recommendation to search, advertising, and inferring personal details about users. Users lacked any meaningful control over how personal information was used for AI-fueled systems.
- The trend among the Companies was that they failed to adequately protect children and teens—this was especially true of teens, who are not covered by the Children’s Online Privacy Protection Rule (“COPPA Rule”)
- Data abuses can fuel market dominance, and market dominance can, in turn, further enable data abuses and practices that harm consumers.
Everything Is Awesome
As I was reading, these are some things that stood out to me. If you're technical and have been paying attention, none of this will really be surprising.
In continued practice, emphasis is mine.
We start by seeing that they can get pretty granular with what we're doing.
"...opportunities abound for social media companies to collect more and more data about the actions, behaviors, and preferences of consumers, including details as minute as what you clicked on with your mouse."
And they take that activity and feed it through algorithms to get us to scroll longer.
"Since greater “User Engagement” means greater opportunities for monetization through advertising, many also have designed and relied on Algorithms that work to prioritize showing content that fuels the most User Engagement more than anything else..."
Zooming out, we see that we are in fact the product:
Providing Digital Advertising Services can provide an incentive to compile extensive information about users, both on- and off-line, to offer targeted advertising and increase advertising revenues for the Company. As a result, while all of these SMVSSs are “free” in the sense of being zero price (or have free versions available), consumers effectively pay through their data and information.
Specific Data Points
This is a non-exhaustive list of items that are being collected. Remember, the technology to scrape details from your personal life has gotten even better since the time frame this report examined.
Starting simple, they know your name.
First and last name
It seems they also know where you live.
Home or other physical address, including street name and name of city or town
And also, where you are at any given point in time.
Other information about the location of the individual, including but not limited to cellular tower information, fine or coarse location, or GPS coordinates
They know where you are spending time online.
Email address or other online contact information, such as instant Messaging user identifier or screen name
This wouldn't contribute to spam calls, would it?
telephone number
Different companies assign identifiers in different ways. None of them are particularly compelling for consumer privacy.
a persistent identifier, such as a customer number held in a "cookie", a static IP address, a device identifier, a device fingerprint, a hashed identifier, or a processor serial number
They are reading your text messages. And emails. And literally everything else that goes through their ecosystems.
non-public Communications and content, Including, but not limited to, e-mail, text messages, contacts, photos, videos, audio, or other digital images or audio content
They know where you're going online:
Internet browsing history, search history, or list of URLs visited
They don't collect data in incognito, right? Unfortunately, they did and probably will again.
They also know what you're watching.
video, audio, cable, or TV viewing history
I'm not sure what the overlap between bio-metric security and bio-metric health data points might be:
biometric data
But, they know how sick you are. Especially if you have health insurance. Maybe not having health insurance is actually a privacy hack?
health or medical information
And they know demographically where you fit in:
characteristics of human populations, such as:
age,
ethnicity,
race,
sex,
disability,
and socio-economic information
And my personal favorite:
any other information associated with that User or Device
Metrics on your activity within a given platform are obviously tracked:
The Companies reported collecting between five and 135 User Metrics on their SMVSSs, with an average of 28 per SMVSS
Those preferences and attributes you create are also part of this dataset:
ranging from zero User Attributes to an indeterminate number of User Attributes
They also know what we're buying:
Most Companies stated that they deliberately collected information regarding consumers’ shopping behaviors
And they know what we're interested in:
Several Companies reported having information regarding users’ interests. The Companies primarily used such user interests for targeted advertising purpose
When do User Interests and Demographic Info overlap? Probably more than we'd like.
Of particular interest, some Companies revealed user interest categories that are more akin to Demographic Information. For example, some Companies’ user interest categories revealed parental status (e.g., user interest category for “baby, kids and maternity”) or marital status (e.g., “newlyweds” or “divorce support”)
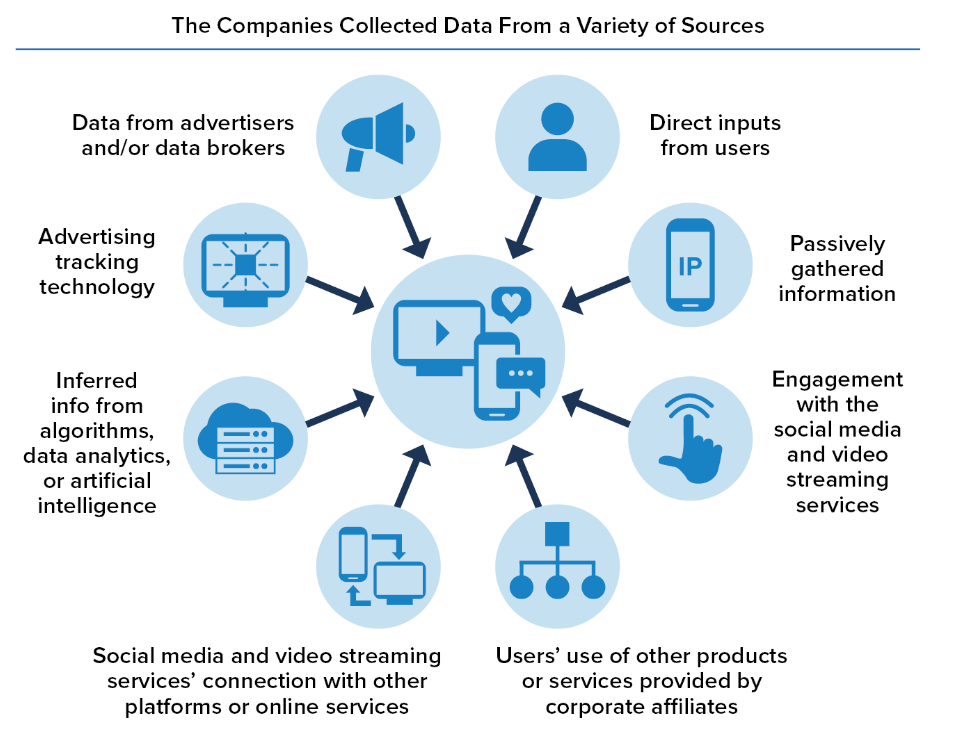
Nobody Knows?
This is pretty crazy to me: their systems are built to track us and sell our data, but they can't figure out who they sold or gave that data to? Sounds like they need to aim that tracking infrastructure back at their own internal processes.
No Company provided a comprehensive list of all third-party entities that they shared Personal Information with. Some Companies provided illustrative examples, whereas others claimed that this request was impossible. A few Companies provided only the names of third-party entities with which the Company had entered a formal contract, thus omitting third parties that the Companies shared with that were not subject to contracts.
Age-Verification Isn't Protection
When talking to others about protecting children and teens online, the most prominent talking point seems to be expanding the age-verification idea: that a company needs to gather even more information about you to ensure you are old enough to access a website.
The real-world implication would be having to provide a state-issued ID to access many websites, which is why we've seen Pornhub pull out of different states (pun intended.)
But, these social media companies don't even discriminate teens from adults anyways:
Most of the Companies did not report implementing any additional safeguards around sharing information collected from Children or Teens
The report continues:
Moreover, no Companies reported having sharing practices that treat the information collected from a user known to be aged thirteen to seventeen differently from an adult’s information.
I guess 13 is the new 18 for data privacy?
Among other things, this shows that any privacy protections that were present for Children on a given SMVSS disappeared the moment that Child turned thirteen.
Buying Data Is Easy
Data brokers and third-party data sharing is a problem. You may think that it's just TikTok stealing our data for foreign governments, but sadly it's pretty common:
Of the Companies that did identify the third parties with whom they shared Personal Information, many of these third parties were located outside of the United States. For example, some third parties that received users’ Personal Information were located in China, Hong Kong, Singapore, India, the Philippines and Cyprus. Such sharing raises concerns about the Companies sharing U.S. consumers’ Personal Information in a way that may expose that data to potential collection by foreign governments.
Did I mentioned that compliance is theater?
In addition, no Company described any audit or other ongoing diligence to ensure that those entities receiving the information were complying with any governing use restrictions in its contracts or terms of service. Rather, many Companies appeared to rely on the existence of such agreements to meet their data privacy obligations
This isn't surprising, and it's a good reason why you should occasionally go back and delete accounts you are no longer using. (Pro-Tip: use your Password managers to find and remove accounts you no longer utilize)
Generally speaking, most Companies did not proactively delete inactive or abandoned accounts.
But sadly, sometimes your data doesn't get deleted even when requested.
For example, instead of permanently deleting data, some Companies instead reported de-identifying such data.
In the US, we've got limited rights compared to our European counterparts - largely because Congress hasn't acted:
All of the Companies’ SMVSSs operate both in the United States and Europe.
....
Only a few Companies reported that they extended to U.S. users the same protections they provided to European users under the GDPR
At least they are testing that what few controls we have are actually working, right?
Despite generally having vast amounts of information on consumers’ user experiences when it comes to advertising and User Engagement, about half of the Companies did not do any testing to ensure that consumers could exercise these privacy choices. The other Companies did not do any analyses or testing of user interfaces during the time period in question and made no substantive changes to the interfaces.
I bet they wouldn't share our data across business units, would they?
Many SMVSSs are part of extensive corporate conglomerates—including those active in foreign countries—that provide a multitude of products and services beyond SMVSSs.
Data Retention
This summary is worth reading in whole - the default contract language for data sharing needs greatly improved:
Our review found that few Companies had transparent and specific data retention policies (e.g., a specific retention period for a piece of consumer data). The promise to retain data only as long as there is a “business purpose” is illusory—without specific and clear restrictions on what constitutes such a purpose, Companies can use a vague policy to indefinitely retain consumer data without any intent to ever delete it. The Companies were unclear on what would constitute a “business purpose.” This terminology is open-ended and provides no clarity on a Company’s practices. And, with the ever-increasing presence of AI, Companies may argue that training AI models is a “business purpose” that justifies retaining consumer data indefinitely.
It's hard to figure out what's going on anyways:
However, Commission staff was often unable to decipher such policies and notices and clearly ascertain the Companies’ actual practices.
They go on to say:
If attorneys and technologists with privacy expertise cannot clearly and with certainty determine an SMVSS’s practices from such policies, it is unclear how the average consumer would be able to understand them.
Data Collection

{kind=link}
We need to update the "The More You Know" PSA for modern times:
It is far from clear that users know the extent to which they are being tracked when they engage with a given SMVSS; it is even more unlikely that consumers know that even their activity off of many SMVSS may be automatically collected and shared with the SMVSS.
Since teens are essentially adults in the eyes of the data collection industry, they are in the dragnet as well.
Children and Teens spend a significant amount of time online. A recent survey found that 88% of teens between thirteen and eighteen have their own smartphone, and 57% of children between eight and twelve have their own tablet.
Which leads to this (mostly expected as a result of usage):
The more time Children and Teens spend online, the more likely they are to have their information collected and see ads.
They go on to reference the incentive issue from earlier:
It is no surprise then, as previously noted, that the Companies reported studying and analyzing User Engagement to serve content, including advertising content, to users, as targeted advertising incentivizes engagement, which in turn incentivizes keeping Children and Teens online.
This is a stupid statistic I wish I had never read:
According to one estimate, some Teens may see as many as 1,260 ads per day
Apparently, the FTC just discovered modern content-marketing while researching this report (/sarcasm):
These harms are particularly difficult for Children and Teens to avoid because frequently the advertising content is blurred—i.e., blended into the surrounding content—which allows marketers to disguise advertising and the persuasive intent of that content.
They disabled account creation for children (under 13) unless the platform had a specific "Kid" type restricted account (which barred advertisements or restricted targeted ads.)
With respect to Children, most Companies stated that they prevented Children from creating accounts
However, teens (13-17) could create accounts at will:
With respect to Teens, almost all of the Companies permitted Teens to create accounts.
Despite not limiting data collection of teens, (to their credit) they did limit advertising to them:
However, when it came to advertising, some Companies reported distinct advertising practices with respect to Teens, such as limiting the types of ads that can be seen by Teens.
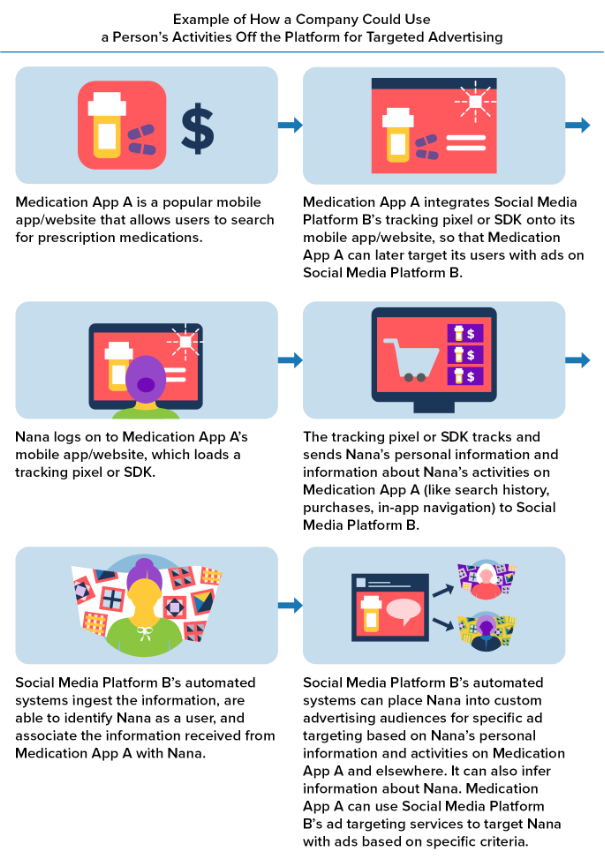
Pixels Are Everywhere
Advertising technology (ad-tech) is prevalent, normalized, and horrible.
For example, these tracking technologies transmitted personal data such as how a user interacted with a web page or app, including specific items a user purchased, search terms the user entered, or information a user typed into a form on the page or app.
It's super easy to detect and avoid, right?
Much of this type of tracking occurs behind the scenes, with users unaware and unable to avoid what’s happening.
Some fun real world implications:
For example, in United States v. GoodRx, the FTC alleged that tracking pixels made available by a Company allowed GoodRx to share personal health information, such as particular medications purchased by users and health conditions, with SMVSSs so GoodRx could target these users with health-related advertisements.
As a reminder, the government can request info from these companies, too. So if the data is shared with a SMVSS, it can be requested and subpoenaed by state and federal actors fairly trivially.
It's happened before, so I would expect it to continue. Another example from the report:
Similarly, in United States v. Easy Healthcare, the FTC alleged that an SDK offered by a Company’s corporate parent allowed the developer of a pregnancy and fertility app to transmit the identifiable health information (including information about users’ fertility and pregnancies) of users of the app to the Company’s parent for advertising purposes without providing users notice or obtaining users’ affirmative express consent
Machine-Learning, AI, and Algorithms
The most common usage of these technologies:
- for content recommendation, personalization, and search functionality, and to boost and measure User Engagement;
- for content moderation purposes or in connection with safety and security efforts;
- to target and facilitate advertising;
- to infer information about users; and for other business purposes, such as to inform internal strategic business decisions or to conduct research.
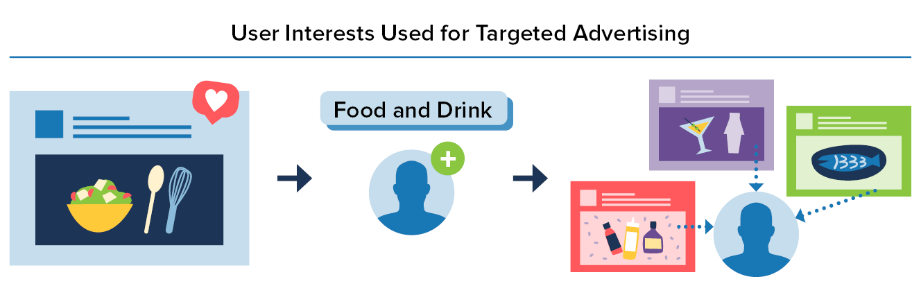
Most used these technologies for a variety of decision-making functions that the Companies described as key to the functioning of their services at a large scale, including the SMVSSs directed to Children and those that permit Teens to use their services.
Yet another thing we should probably try to stop from happening:
In some cases, the services directed to Children use Algorithms, Data Analytics, or AI in the same manner as the SMVSSs that are not directed to Children
Looks like humans are probably looking at data manually in some cases?
At least one Company did not appear to use Classifiers, and instead employed a manual registration and annotation process for unlabeled or unstructured data.
For reference, here's what a Classifier is per the FTC report:
The Order defines “Classifiers” as “a machine-based process that sorts unlabeled data into categories.”
User Engagement = Money
Since we've already established that user engagement is prioritized, it's easy to infer (hey, they started it) that their algorithms and AI will prioritize content that will keep you scrolling - not necessarily highlighting content that you actually care about.
Most Companies said they relied on Algorithms, Data Analytics, or AI for content personalization—to determine, based on users’ information and activities, which content (such as user-generated pictures, videos, or other content) users were presented with, to recommend and present content in response to search queries, or to surface topics, content, and trends.
Despite the fairly innocuous graphic...
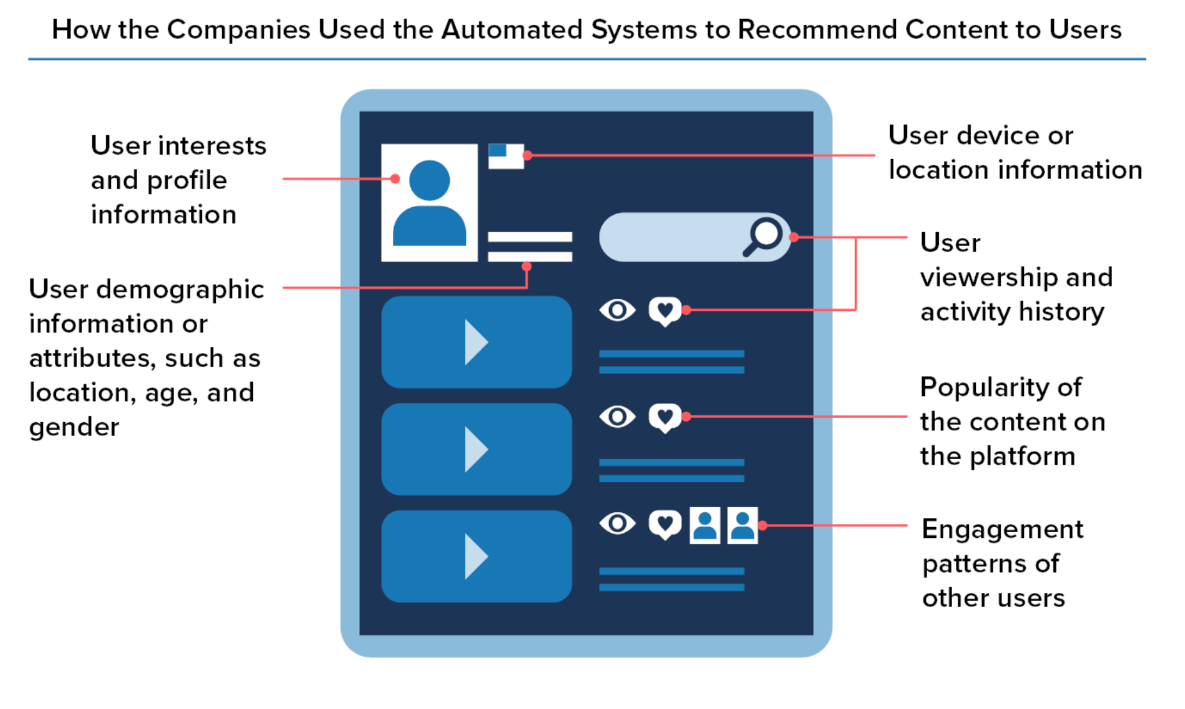
In general, the Companies described complex algorithmic and machine learning models that looked at, weighed, or ranked a large number of data points, sometimes called “signals,” that were intended to boost User Engagement and keep users on the platforms.
Some more examples of user activity:
user viewership and activity history, such as
views or viewing history,
search queries,
replies or comments,
the type of content a user interacted with and its popularity,
time spent viewing content,
or a user’s interaction or feedback with the content (“likes” or sharing), click-through rate,
or accounts,
groups,
pages,
or content a user followed,
and the content they posted;
But anyway, back to saving the kids?
At least one Child-directed SMVSS reported using automated filters to determine if content is “family-friendly,” and therefore eligible for inclusion on the platform
So, they can reliably guess the age of the user...
Algorithms, Data Analytics, or AI were often used to infer characteristics and -Demographic Information such as age and date of birth, gender, location, Familial Status or Family Relationships, as well as other categories such as language
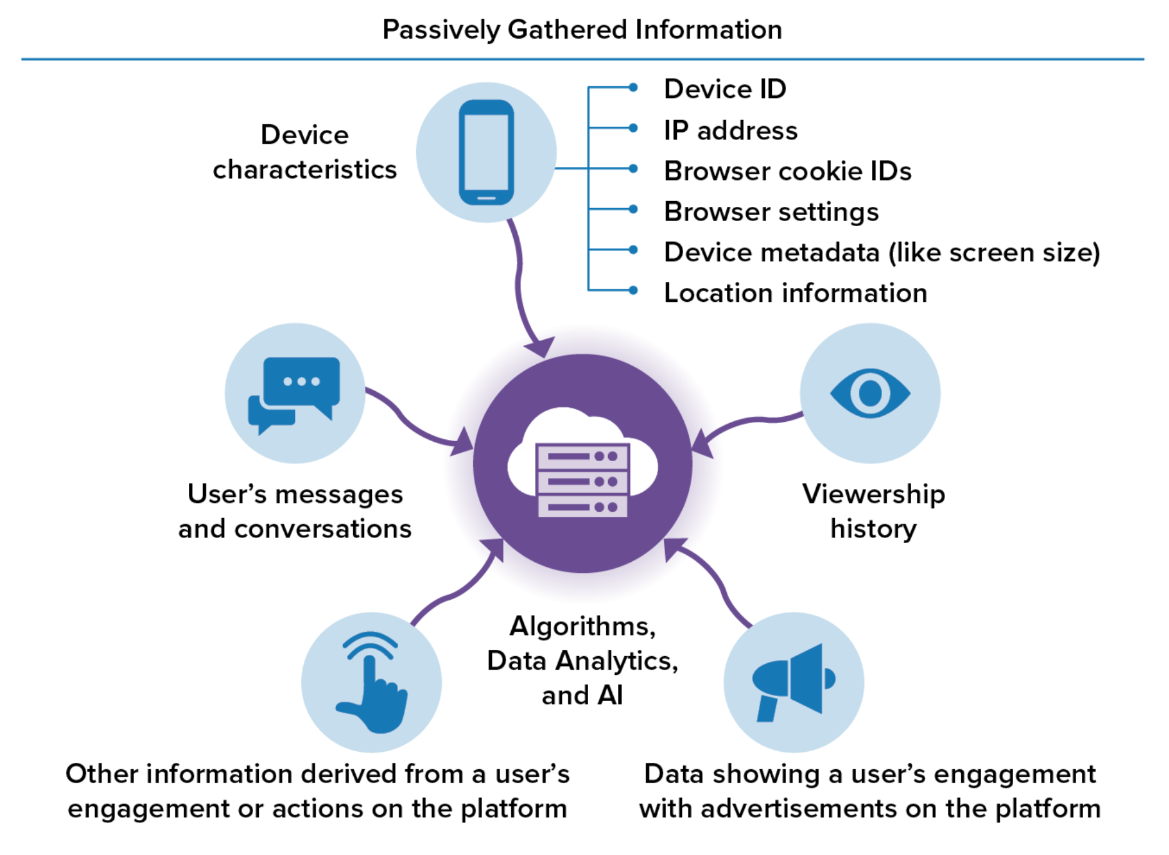
A quick reminder that doing things that are fairly normal can result in other people's data being ingested by the ad-tech machine:
Some Companies reported ingesting both user and non-user data, but at least one Company said it did not intentionally ingest non-user data
What exactly does that look like in the real-world? Things like syncing contacts and uploading marketing lists are often included in the data collection and processing.
Examples included Personal Information about non-users when a user uploaded and synced their contacts list or when advertisers uploaded Personal Information (such as an email address) about all of their customers (users and non-users alike) for advertising purposes, such as to build targeted advertising audiences
So maybe think twice before you upload all your contacts to every app that asks for them.
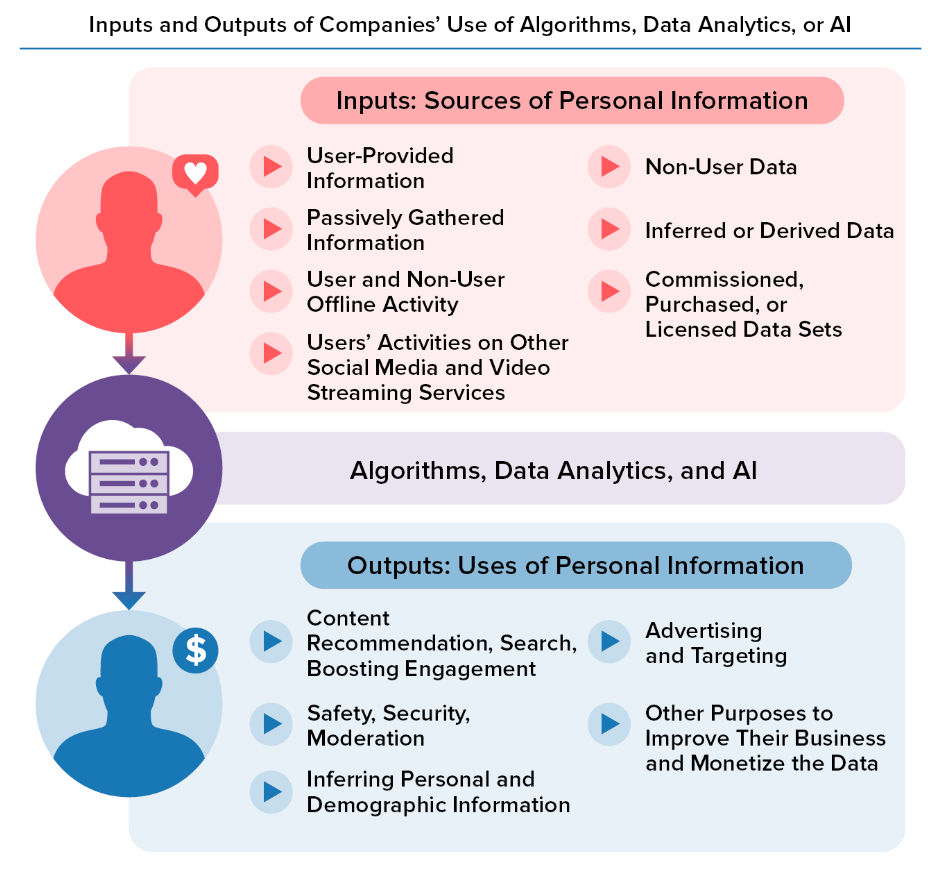
I Have The Power
Actually, we aren't He-Man in this example. We do not have the power.
- User and non-user information was, by default, ingested into and used by Algorithms, Data Analytics, or AI.
- No Universal Opt-In or Opt-Out
- Users and non-users likely did not know, did not understand, and did not control the wide-ranging collection and uses of their data by the Companies’ Algorithms, Data Analytics, or AI.
- Inadequate explanations of how Algorithms, Data Analytics, or AI operated
- Potential harms from inferred sensitive data: the Companies used Algorithms, Data Analytics, or AI to profile, as well as infer or derive more personal details about individuals, such as their families, interests, income, personal relationships, and lifestyle details.
- Inferring information may weaken the effectiveness of consumer choice
- Users and non-users did not know of and could not fix, address, or correct automated decisions about them that were inaccurate, or that may have been based on flawed or inaccurate information.
They did give us some options:
Rather, some Companies’ efforts were limited to allowing consumers to view or make choices relating to advertising and ad-targeting, such as opting out of targeted advertising or use of data by advertising Algorithms, or requesting to download or delete data.
But to take advantage of those options...well....Shall We Play A Game?
Moreover, this required some affirmative action by the consumer, such as to find and navigate through a control or settings menu
Often, the opt-outs don't stop them from using your data, just what ads you see.
In addition, these opt-outs appeared limited to affecting the advertisements served to a user or preventing ad-targeting based on Personal Information on a going-forward basis, and they likely would not change decisions, inferences, or outcomes already made by an automated system, such as the detailed categories of inferred Demographic Information discussed above
Seriously, back to saving the kids.
We continue to see that the baseline goal is to keep you engaged on their platform.
As discussed above in Section VI.A.1, the Companies relied on Algorithms, Data Analytics, or AI to determine what content to serve to users. These models generally prioritized showing content that gets the most User Engagement (view time, likes, comments, or content that is trending or popular)
The report then references some specifics, such as the Surgeon General Advisory report titled Social Media and Youth Mental Health and then goes on to state the advisory "noted that excessive and problematic use of social media may harm children and teens by disrupting healthy behaviors and lead to habit formation."
So the incentive to keep kids online (and moreover users in general) aligns with harm for the end-user, but profit for the company. Yikes.
Turn off your notifications!
Push notifications, autoplay, infinite scroll, quantifying and displaying popularity (i.e., ‘likes’), and algorithms that leverage user data to serve content recommendations are some examples of these features that maximize engagement.
At least it's not addicting...
Further, some researchers believe that social media exposure can overstimulate the reward center in the brain and, when the stimulation becomes excessive, can trigger pathways comparable to addiction.
The habit forming reinforces user engagement on their platform and...well, read on:
Small studies have shown that people with frequent and problematic social media use can experience changes in brain structure similar to changes seen in individuals with substance use or gambling addictions
So yeah, they are out here doing God's work and saving the kids:
In the absence of rules or laws that afford protections to Teens’ privacy in the digital world, many Companies elected to treat Teens just like adults on SMVSSs
Self-Regulation Rarely Works For Consumers
I'd argue that call authentication hasn't fixed robocalls, so why should we expect self-regulation to work here?
Some Companies reported internal teams or organizations dedicated to company-wide oversight of Algorithms, Data Analytics, or AI, such as to address concerns relating to ethics, bias, inclusion, and fairness in the use of these technologies in their product.
I have to assume they just ignored the recommendations from their internal teams in favor of profits. That is what matters to public companies and their shareholders after-all.
...the authority of these internal organizations was not always clear, and their role appeared limited to consulting and offering guidance to the teams that developed the models.
They continue:
It also was not clear whether any of their recommendations were binding.
During this self-regulation, we find more human review with limited transparency on when...
Most Companies used human review in limited contexts. Human review was most often reported in the context of Algorithms, Data Analytics, and AI relating to content moderation, such as sampling the outputs of the system’s decisions.
It's just easier to assume that everything can be seen by a human...
But it was not always clear how and at what stage human reviewers came into the picture; whether only certain decisions already made by automated systems were subject to human review; and which automated decisions were not subject to human review.
And who are the ones reviewing our data? We have no idea.
Even assuming human review was involved, the Companies did not specify the qualifications of reviewers, whether reviewers were employees or external to the Company, and whether reviewers represented diverse backgrounds, viewpoints, and perspectives
Still Saving Kids, Part III
It's fairly common knowledge that teens and kids are using social media.
Research indicates that approximately 95% of teenagers and 40% of children between the ages of eight and 12 years old use some form of social media
Remember, there is no requirement to be an adult.
No Company reported that the intended user age for its SMVSS, or those allowed to create accounts, had to be over the age of eighteen
They can't miss out on that spending power:
Overall, most Companies reported that their SMVSSs were not directed to Children or to Teens, but they nevertheless permitted anyone thirteen or over to create an account with few limitations
Actually, we're just skating the rules - a reminder that compliance is theater:
It is possible that such SMVSSs refused to infer any age range below thirteen years old for the fear of being deemed to have “actual knowledge” under the COPPA Rule and thus being liable for such legal requirements
That means that unless you self-report as a child, you'll get the adult experience.
This leads to the absurd result wherein the Companies stated that their Algorithms, Data Analytics, or AI could detect if a user was between 13 and 14 years of age, but if a user was under thirteen then the Companies stated they had to rely on other means (e.g., self-reporting) to determine that a user was a Child.
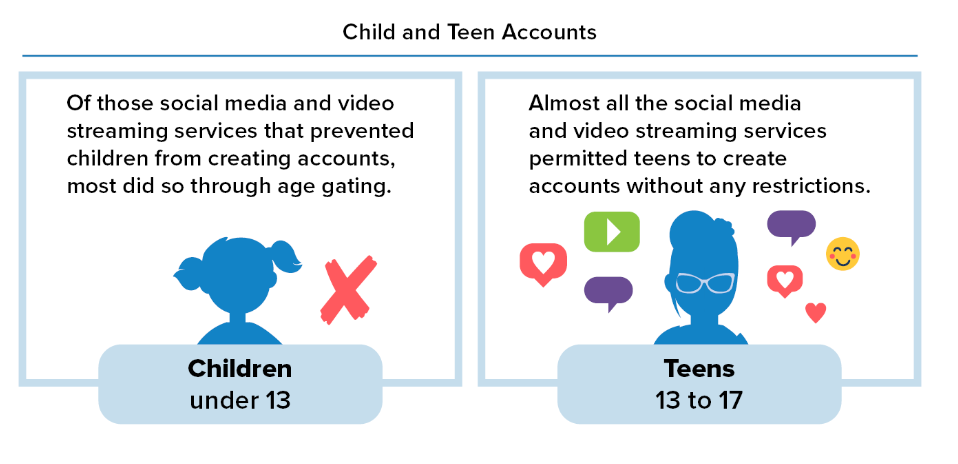
You'll need to know this definition:
Age gating refers to a process wherein a service requires a user to enter or provide their age or date of birth when they attempt to register for a service
But, can you just lie? It seems like for most age verification, you can enter any date of birth you want into the box.
But also, there's this - I'm sure your 10-year old read the Terms of Service:
A few Companies reported that they only contractually prohibited Children from creating accounts on an SMVSS, meaning that there was no actual mechanism in place to stop a Child from creating an account.
However, you might get flagged later if other users or inferences indicate you might be a kid:
If a Child managed to create an account, most of these SMVSSs provided other users with a means to report the underage user. A few SMVSSs reported using other methods to discover Child users, including having the SMVSS content reviewers flag content that appeared to come from an underage user or tracking when a user changed their date of birth to be under thirteen years old
I once changed my companies Twitter handle's date of birth to the date I registered my business in Ohio, which was only 10 years old at the time. They immediately locked my account and made me prove I was old-enough.
Anyways, back to the FTC report. Parental control at it's finest?
Most Companies explicitly reported that they would not do anything if they learned that a Teen user had created an SMVSS account without parental consent.
Consider the children saved:
This indicates that these Companies did not consider Teens to be distinct or different from adult users with respect to data collection and use practices and processed Teen user data as if it were adult user data, despite the potential effects on Teen mental health...
Well, this is good I suppose:
Some Company SMVSSs would allow parents or legal guardians to review or access the Personal Information collected from a user under the age of eighteen, but would require that the parent or legal guardian verify both the parent/legal guardian’s and Teen user’s identities.
But...this? It seems like parents/guardians should have some level of control over their kids data. Maybe I'm off base here.
Most Companies reported that they either would not fulfill a parent or legal guardian’s request to delete a Teen user’s data or required all such requests to come through the Teen user’s account (and thus presumably through the Teen).
The key findings?
- SMVSSs bury their heads in the sand when it comes to Children using their services
- Only some SMVSSs had a process by which parents/legal guardians could request access to the Personal Information collected from their Child.
- The SMVSSs often treated Teens as if they were traditional adult users
Consumer Harm
We all know that monopolies are bad, right?
When companies eliminate competitive threats and do not face adequate competitive checks, quality, innovation, and customer service suffer.
This seems like every big-tech company:
Further, in digital markets, including AI, acquiring and maintaining access to significant user data can be a path to achieving market dominance and building competitive moats that lock out rivals
It's okay, just as long as the shareholders are making money.
The competitive value of user data can incentivize firms to prioritize acquiring it, even at the expense of user privacy and sometimes the law.
FTC Staff Recommendations
A summary of recommendations provided as part of the 6b report Executive Summary, emphasis mine.
- Companies can and should do more to protect consumers’ privacy, and Congress should enact comprehensive federal privacy legislation that limits surveillance and grants consumers data rights.
- Companies should implement more safeguards when it comes to advertising, especially surrounding the receipt or use of sensitive personal information.
- Companies should put users in control of—and be transparent about—the data that powers automated decision-making systems, and should implement more robust safeguards that protect users.
- Companies should implement policies that would ensure greater protection of children and teens.
- Firms must compete on the merits to avoid running afoul of the antitrust laws.
That last point, the way I understand it, is essentially a call for antitrust enforcement to collectively grow a backbone.
The report has a detailed set of staff recommendations at the end which go into each of these points in finer detail with more granular recommendations if you're so inclined.
Conclusion
Advocate for data privacy and vote for candidates who can articulate, discuss, and defend our digital rights.
Other ways you can help:
- Use an ad-blocker and prefer Firefox (for now)
- Use Privacy Badger from the EFF
- Stop clicking "Accept all cookies" and instead opt-out of collection
- Read, share, and donate to the Electronic Frontier Foundation (EFF)
- Read, share, and donate to The Repair Association at Repair.org
- Read, share, and subscribe to 404Media
- Support small and local businesses instead of buying things online




